Thông tin doanh nghiệp
Dù bạn là người mới làm SEO hay đã có kinh nghiệm, việc hiểu đúng Crawl và Index là gì là bước bắt buộc để tối ưu hiệu quả hiển thị trên Google. Hai thuật ngữ tưởng chừng cơ bản này lại chính là cánh cổng đầu tiên quyết định nội dung của bạn có được xuất hiện trên kết quả tìm kiếm hay không.
Định nghĩa Crawl và Index là gì?
Crawl và Index là hai bước đầu tiên trong quy trình xử lý thông tin của công cụ tìm kiếm như Google.
Mở rộng ý nghĩa và vai trò thực tế
Hiểu đơn giản, Crawl như việc "Google đến gõ cửa" website bạn để xem có gì mới, còn Index là "ghi chép lại" những gì đã xem vào một thư viện khổng lồ – nơi nội dung của bạn sẽ được so sánh và hiển thị nếu phù hợp với truy vấn người dùng.
Nếu một trang không được crawl thì chắc chắn không thể được index. Nhưng nếu trang đã được crawl mà không được index, có thể là do các lý do như chất lượng nội dung kém, trùng lặp, bị chặn bởi robots.txt, hoặc gặp lỗi kỹ thuật SEO.
Hai khái niệm này không chỉ quan trọng về mặt kỹ thuật, mà còn ảnh hưởng trực tiếp đến hiệu quả hiển thị nội dung, tối ưu crawl budget, và chiến lược SEO tổng thể – đặc biệt trong thời kỳ Google ưu tiên nội dung chất lượng và trải nghiệm người dùng như hiện nay.

Nhiều người thường nhầm lẫn Crawl và Index chỉ là “Google đọc trang rồi lưu lại”. Trên thực tế, cả hai đều là những tiến trình kỹ thuật phức tạp, với hệ thống backend khổng lồ phía sau. Hiểu rõ cách chúng hoạt động giúp bạn kiểm soát tốt hơn chiến lược SEO của mình.
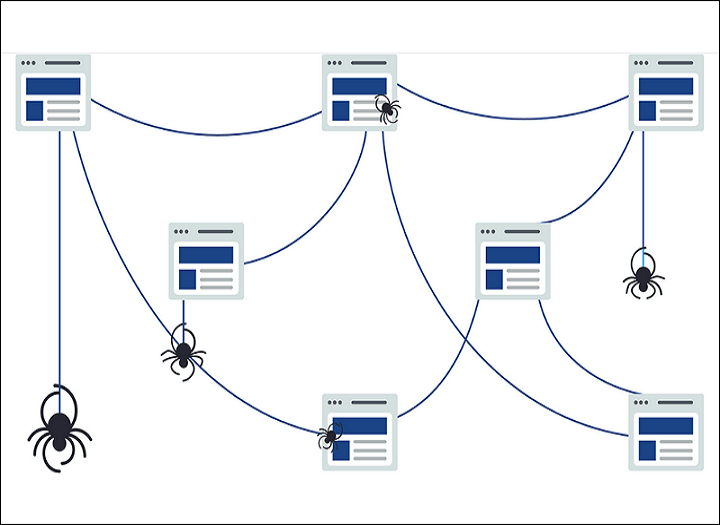
Quy trình Crawl bắt đầu từ một danh sách URL đã biết (seed list) hoặc các liên kết thu thập từ sitemap. Công cụ phổ biến nhất là Googlebot, sử dụng các thuật toán để:
Một yếu tố quan trọng là Crawl Budget – tức là giới hạn tài nguyên Googlebot dành cho website bạn. Những trang có tốc độ tải chậm, nhiều lỗi 5xx, hoặc nội dung trùng lặp sẽ bị giảm tần suất crawl.
Sau khi dữ liệu được Crawl, công cụ tìm kiếm sẽ:
Cần lưu ý, không phải trang nào cũng được index. Ví dụ: Trang bị chặn bởi noindex tag, robots.txt hoặc không có giá trị SEO cũng sẽ bị loại khỏi kết quả tìm kiếm.
Không phải mọi quá trình Crawl hay Index đều giống nhau. Trong quá trình tối ưu SEO, bạn sẽ gặp nhiều biến thể khác nhau của hai khái niệm này. Mỗi dạng lại có cách vận hành, cảnh báo và tác động khác biệt đến khả năng xuất hiện trên Google Search.
Là khi Googlebot thu thập toàn bộ nội dung trang và liên kết nội bộ. Đây là mục tiêu lý tưởng trong SEO.
Xảy ra khi Google chỉ crawl một phần nội dung do giới hạn tài nguyên hoặc phát hiện nội dung trùng lặp, load chậm.
Google ưu tiên thu thập URL được khai báo trong sitemap.xml – giúp kiểm soát crawl tốt hơn.
Trang không được crawl do robots.txt hoặc thẻ meta robots (noindex, nofollow) – ảnh hưởng trực tiếp đến Index.
Áp dụng với website có tần suất cập nhật nội dung cao, giúp nội dung mới được phát hiện nhanh hơn.
Trang được index thành công, có thể hiển thị trên kết quả tìm kiếm Google.
Google đã biết tới trang nhưng chưa index, có thể do chất lượng nội dung chưa đạt hoặc cần thời gian xem xét.
Google đã crawl nhưng chưa đưa vào index – cảnh báo SEO phổ biến, thường gặp trên các trang nội dung yếu hoặc thiếu liên kết nội bộ.
Trang hiển thị nội dung nhưng được đánh giá là không có giá trị thực (ví dụ: trang trắng, thiếu nội dung, không có CTA rõ ràng).
Trang bị đánh dấu trùng lặp nhưng không có canonical rõ ràng, khiến Google không biết nên index phiên bản nào.
Một trong những nhầm lẫn phổ biến nhất của người làm SEO là đánh đồng Crawl với Index. Dù liên kết chặt chẽ, hai khái niệm này phục vụ hai vai trò hoàn toàn khác nhau trong chuỗi xử lý của công cụ tìm kiếm.
|
Tiêu chí |
Crawl |
Index |
|---|---|---|
|
Bản chất |
Thu thập thông tin từ website |
Phân tích và lưu trữ nội dung |
|
Công cụ |
Googlebot, Bingbot, AhrefsBot,… |
Indexing engine của công cụ tìm kiếm |
|
Giai đoạn |
Diễn ra trước |
Diễn ra sau khi Crawl |
|
Tác động nếu không thực hiện |
Trang không được phát hiện |
Trang không hiển thị trên Google |
|
Kiểm tra trạng thái |
Log server, Google Search Console |
Google Search Console – tab Coverage |
|
Yếu tố ảnh hưởng |
Crawl budget, tốc độ tải, lỗi 404 |
Chất lượng nội dung, canonical, E-E-A-T |
Điểm quan trọng: Bạn có thể bị crawl mà không được index, nhưng không thể được index nếu chưa được crawl.
Một website dù đẹp đến đâu cũng vô nghĩa nếu không ai tìm thấy nó trên Google. Chính vì thế, việc tối ưu quy trình Crawl – Index không chỉ là kỹ thuật SEO cơ bản, mà còn ảnh hưởng trực tiếp đến khả năng tiếp cận khách hàng tiềm năng.
Nhiều người khi mới làm SEO thường nhầm lẫn bản chất của hai khái niệm này hoặc bỏ qua các tín hiệu kỹ thuật quan trọng, dẫn đến website không được index, traffic giảm và thứ hạng không cải thiện.
Để cạnh tranh trên Google Search trong thời đại SGE (Search Generative Experience), không chỉ dừng lại ở việc biết Crawl và Index là gì, mà bạn cần biết cách tối ưu toàn diện quy trình này để tăng tốc độ hiển thị, giảm lỗi kỹ thuật và nâng cao thứ hạng tìm kiếm.
Hiểu rõ Crawl và Index là gì không chỉ giúp bạn khắc phục lỗi kỹ thuật SEO mà còn mở ra cách tiếp cận tối ưu nội dung hiệu quả hơn. Đây là cặp khái niệm quan trọng bậc nhất trong hành trình một trang web “xuất hiện” trên Google. Khi làm chủ được quy trình này, bạn có thể kiểm soát tốt hơn thứ hạng, traffic và trải nghiệm tìm kiếm mà nội dung mang lại. Nếu muốn nâng cao hơn nữa, hãy khám phá thêm về cách tối ưu Crawl Budget hoặc kỹ thuật xử lý Index Coverage.
Không. Crawl diễn ra trước, khi Googlebot truy cập trang. Index chỉ xảy ra nếu trang được đánh giá đủ điều kiện để lưu trữ vào cơ sở dữ liệu của Google.
Bạn có thể dùng lệnh site:yourdomain.com/page-url trên Google hoặc kiểm tra bằng “URL Inspection” trong Google Search Console.
Không bắt buộc, nhưng gửi sitemap giúp Google phát hiện URL nhanh hơn, đặc biệt với website lớn hoặc có nhiều trang con mới.
Crawl budget là lượng tài nguyên Googlebot phân bổ cho website bạn. Quản lý tốt giúp Google crawl những trang có giá trị nhanh và thường xuyên hơn.
Có thể do nội dung mỏng, trùng lặp, trang không có liên kết nội bộ, tốc độ tải chậm hoặc thiếu tín hiệu chất lượng như E-E-A-T.
Bạn không thể ép buộc, nhưng có thể yêu cầu index thủ công qua Google Search Console và đảm bảo nội dung đủ chất lượng, tối ưu kỹ thuật.