Thông tin doanh nghiệp

Không phải ai làm SEO cũng hiểu đúng vai trò của file robots.txt. Trong khi một dòng “Disallow: /” sai lệch có thể khiến cả website biến mất khỏi Google, thì một cú “Allow: /” hớ hênh lại phơi bày dữ liệu nội bộ cho bot và scraper. Vậy tại sao robots.txt nhỏ bé này lại ảnh hưởng nghiêm trọng đến Technical SEO? Hãy cùng phân tích bối cảnh và lý do khiến việc chặn và mở Robots.txt trở thành yếu tố sống còn của tối ưu tìm kiếm.
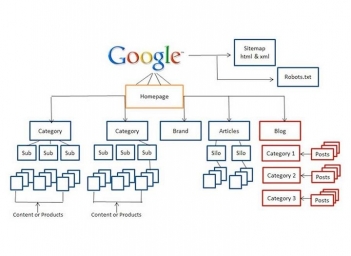
Robots.txt là file văn bản nằm ở thư mục gốc của website, dùng để hướng dẫn các bot tìm kiếm (như Googlebot, Bingbot...) nên hoặc không nên thu thập (crawl) phần nào trên site. Nó không phải công cụ bảo mật, cũng không kiểm soát việc index (lập chỉ mục), nhưng lại đóng vai trò thiết yếu trong việc:
Trong thực tế, có nhiều tình huống website cần “đóng cửa” tạm thời với bot (ví dụ: khi đang phát triển, cập nhật lớn, lỗi nghiêm trọng...), nhưng cũng có lúc cần “mở toang” để Google lập chỉ mục toàn bộ. Biết khi nào nên chặn và mở Robots.txt là một kỹ năng quan trọng giúp tránh sai lầm gây thiệt hại lớn cho hiệu suất SEO kỹ thuật của site.

Trong SEO kỹ thuật, không có câu trả lời “nên chặn” hay “nên mở” một cách tuyệt đối. Mọi quyết định liên quan đến chặn và mở Robots.txt cần dựa trên bối cảnh cụ thể, mục tiêu của website, và cả cách các bot hiểu nội dung. Để không mắc sai lầm, cần nắm vững các yếu tố then chốt sau:
Một robots.txt tốt không chỉ đúng cú pháp mà còn cần tối ưu theo vai trò thư mục, chẳng hạn:
User-agent: *
Disallow: /wp-admin/
Allow: /wp-admin/admin-ajax.php
Disallow: /tag/
Disallow: /*?*
Tóm lại, chặn quá tay có thể khiến website “vô hình” trên Google, nhưng mở toàn bộ lại dễ gây index nội dung rác, duplicate, thậm chí thông tin nhạy cảm. Lựa chọn chặn hay mở phải dựa trên hiểu biết kỹ lưỡng, cập nhật liên tục, và thói quen audit định kỳ file robots.txt.
Không phải lúc nào bạn cũng nên để bot Google tự do truy cập mọi ngóc ngách trên website. Tùy từng giai đoạn phát triển, loại nội dung, hoặc mục tiêu SEO mà bạn cần quyết định nên chặn và mở Robots.txt thế nào cho hiệu quả. Dưới đây là các tình huống điển hình mà chuyên gia kỹ thuật SEO thường xử lý để đạt hiệu suất tối ưu:
Mọi nội dung demo, chưa hoàn thiện, chưa cấu hình SEO đều nên bị chặn hoàn toàn, tránh việc Google index nhầm phiên bản thử nghiệm (rất phổ biến với WordPress hoặc Shopify staging).
➤ Dùng lệnh:
User-agent: *
Disallow: /
Ví dụ: /category/shoes?page=2&sort=desc&utm_campaign=sale
Những URL này không mang lại giá trị SEO nhưng lại tiêu tốn crawl budget.
Như tài liệu nội bộ, thư viện ảnh không dùng cho SEO, endpoint API REST, admin panel...
Tạm thời chặn để bot không thu thập và index nội dung lỗi, gây ảnh hưởng đến xếp hạng.
Khi đó, việc mở robots.txt giúp Googlebot truy cập dễ dàng, tăng tốc độ index.
Cần cho phép bot crawl toàn bộ để đảm bảo nội dung mới được ghi nhận kịp thời.
Việc mở rộng quyền crawl là cần thiết sau khi đã tinh chỉnh phần cần chặn chính xác.
Rất nhiều doanh nghiệp quên chặn staging, khiến Google index bản thử nghiệm với nội dung trùng lặp → bị đánh tụt hạng do duplicate content.
Ví dụ thực tế:
Một agency tại Úc phát hiện site staging nằm ở staging.domain.com bị Google index do quên chặn robots.txt, khiến bản chính ở www.domain.com bị đánh tụt 3 bậc từ khóa vì bị xem là “nội dung sao chép”.
→ Bài học: Luôn chặn site staging, dev hoặc bản backup.
Việc chặn và mở Robots.txt đúng thời điểm không chỉ giúp tăng hiệu quả SEO, mà còn ngăn chặn được nhiều hậu quả đáng tiếc. Dưới đây là những lợi ích và rủi ro đã được kiểm chứng qua thực tế triển khai:
1. Tối ưu Crawl Budget rõ rệt (giảm >60% crawl lãng phí)
Một case thực tế từ Moz cho thấy:
Website e-commerce có >100.000 URL, sau khi chặn các trang lọc, phân trang, ?sort, ?utm=, crawl budget được giảm 68% số URL không cần thiết, tăng tốc độ index trang chính gấp 2 lần.
2. Giảm duplicate content đáng kể
Bằng cách chặn /tag/, /page/2/, hoặc các trang tìm kiếm nội bộ (/search?q=), các công ty có thể loại bỏ đến 40–70% nội dung trùng lặp, giảm nguy cơ bị thuật toán Panda (hoặc tương tự) đánh giá thấp chất lượng site.
3. Tăng hiệu quả index sau khi mở khóa đúng vùng crawl
Sau khi audit robots.txt và “mở khóa” mục /blog/, một trang SaaS B2B tại Canada ghi nhận tăng 48% số lượng trang được index trong 2 tuần, kéo theo lượng traffic tự nhiên tăng 25%.
1. Website biến mất khỏi Google chỉ vì 1 dòng sai
Case phổ biến: Vô tình cấu hình
User-agent: *
Disallow: /
→ Website bị Google deindex toàn bộ chỉ sau vài ngày, tụt hạng thê thảm.
2. URL bị chặn nhưng vẫn xuất hiện trong kết quả tìm kiếm
Google sẽ hiển thị dạng: “Không có thông tin mô tả vì URL bị chặn bởi robots.txt” → Làm giảm tỷ lệ CTR nghiêm trọng do người dùng thiếu thông tin.
3. Chặn hình ảnh hoặc JS/CSS quan trọng → giảm điểm Page Experience
Nếu chặn /wp-content/, /assets/, Googlebot không thể “thấy” website như người dùng → dẫn đến điểm Core Web Vitals kém, ảnh hưởng đến ranking.
4. Dễ bị khai thác thông tin nội bộ
Nếu không chặn các endpoint API, cấu trúc thư mục nhạy cảm, scraper có thể crawl và lấy dữ liệu hàng loạt.
Mỗi website có mục tiêu, quy mô và cấu trúc khác nhau – dẫn đến cách xử lý file robots.txt cũng cần linh hoạt. Dưới đây là những khuyến nghị đã kiểm chứng, phù hợp với từng kịch bản cụ thể trong thực tế.
→ Khuyến nghị: Chặn toàn bộ bot để tránh index nội dung chưa chuẩn SEO
User-agent: *
Disallow: /
Áp dụng cho:
Lưu ý: Sau khi chuyển sang bản chính thức, phải nhớ mở robots.txt, nếu không site sẽ “vô hình” với Google.
→ Khuyến nghị: Chặn bộ lọc, phân trang, UTM... để tiết kiệm crawl budget
User-agent: *
Disallow: /search
Disallow: /*?*
Disallow: /page/
Disallow: /tag/
Áp dụng cho:
Nên mở cho các URL sản phẩm, danh mục chính, bài blog chứa nội dung evergreen.
→ Khuyến nghị: Mở hoàn toàn nếu nội dung cập nhật thường xuyên
User-agent: *
Allow: /
Kèm theo khai báo sitemap:
Sitemap: https://domain.com/sitemap.xml
Áp dụng cho:
→ Khuyến nghị: Chặn endpoint API, route xử lý nội bộ
Disallow: /api/
Disallow: /internal/
Disallow: /wp-json/
Áp dụng cho:
Không có một mẫu robots.txt “vạn năng” cho mọi website, nhưng có những mẫu cấu hình khuyến nghị phổ biến, phù hợp với chuẩn SEO của Google. Dưới đây là gợi ý cấu trúc hoàn chỉnh, kèm theo giải thích từng thành phần.
User-agent: *
Disallow: /wp-admin/
Allow: /wp-admin/admin-ajax.php
Disallow: /tag/
Disallow: /*?*
Disallow: /page/
Disallow: /search
Sitemap: https://www.domain.com/sitemap.xml
Giải thích:
|
Cú pháp |
Ý nghĩa |
Ví dụ |
|---|---|---|
|
* |
đại diện cho mọi ký tự |
/product* sẽ chặn /product, /products/,... |
|
$ |
kết thúc chuỗi |
/*.pdf$ chặn mọi file PDF |
|
Allow |
cho phép truy cập ngoại lệ |
Allow: /images/logo.png |
|
Sitemap |
khai báo sơ đồ website |
Sitemap: https://... |
Ví dụ đúng:
Sitemap: https://domain.com/sitemap.xml
Ví dụ sai:
Khai báo sitemap staging, sitemap không tồn tại → bot crawl thất bại
Nhiều quản trị viên website, kể cả những người làm SEO lâu năm, vẫn mắc những lỗi cơ bản trong việc cấu hình robots.txt, khiến website bị mất index, giảm hạng, thậm chí bị Google phạt mà không hề hay biết. Dưới đây là các sai lầm phổ biến nhất, đi kèm ví dụ thực tế và cách khắc phục hiệu quả.
Đây là lỗi nghiêm trọng nhất – và cũng là lỗi dễ gặp nhất khi triển khai website mới. Trong giai đoạn phát triển, developer thường thêm dòng:
User-agent: *
Disallow: /
Mục đích là để tránh Google index phiên bản chưa hoàn thiện. Tuy nhiên, sau khi site lên production, nhiều người quên không xóa dòng này, khiến cả website bị chặn index hoàn toàn.
Hậu quả:
Giải pháp:
Nhiều người nhầm lẫn giữa “crawl” và “index”. Chặn trong robots.txt chỉ ngăn bot thu thập nội dung – không ngăn việc index nếu có backlink trỏ về. Điều này khiến Google vẫn index trang, nhưng không có nội dung mô tả → ảnh hưởng nghiêm trọng đến UX và CTR.
Ví dụ:
User-agent: *
Disallow: /thank-you
Nếu có ai đó link đến /thank-you, Google có thể vẫn index nó, nhưng hiển thị dạng:
"Không có thông tin mô tả vì bị chặn bởi robots.txt"
Cách đúng:
Một số người cố gắng chặn /wp-content/, /assets/, hoặc thư mục chứa ảnh để “giảm tài nguyên crawl”. Tuy nhiên, nếu Googlebot không thể nhìn thấy giao diện như người dùng, nó sẽ đánh giá thấp trải nghiệm trang (Page Experience), đặc biệt là trong thời kỳ Core Web Vitals trở thành yếu tố xếp hạng chính.
Khuyến nghị:
Một số lỗi ngớ ngẩn nhưng lại rất phổ biến:
Khi đổi URL, chuyển trang, thêm thư mục mới..., file robots.txt cũng cần được cập nhật tương ứng. Nhiều website thay đổi cấu trúc nhưng vẫn dùng robots.txt cũ → gây chặn nhầm hoặc không kiểm soát được crawl.
Checklist kiểm tra robots.txt định kỳ
Tổng kết: Việc cấu hình robots.txt không khó, nhưng cũng không thể cẩu thả. Sai lầm nhỏ trong một dòng lệnh có thể khiến toàn bộ chiến lược SEO sụp đổ. Hãy luôn kiểm tra kỹ, phối hợp chặt chẽ giữa SEOer – dev – content để đảm bảo website vừa an toàn, vừa đạt hiệu suất crawl-index tối đa.
Cấu hình chặn và mở Robots.txt đúng thời điểm giúp kiểm soát hiệu quả crawl budget, tránh rủi ro duplicate content và tăng tốc độ index nội dung quan trọng. Tuy nhiên, nếu dùng sai, nó có thể gây mất index toàn bộ website hoặc khiến nội dung xuất hiện không đầy đủ trên Google. Với từng mục tiêu và giai đoạn khác nhau, hãy điều chỉnh file robots.txt phù hợp và kiểm tra định kỳ. Nếu bạn đang triển khai SEO kỹ thuật, đây là một trong những cấu hình không thể làm qua loa.
Có, nhưng nên kết hợp thêm thẻ noindex nếu không muốn bị index thông qua backlink. Chỉ dùng robots.txt sẽ không ngăn được Google index.
Vì robots.txt chỉ ngăn bot thu thập nội dung, không ngăn việc lập chỉ mục nếu có liên kết ngoài trỏ về URL đó.
Khi site đang phát triển, staging, hoặc đang gặp lỗi lớn cần xử lý gấp. Tuy nhiên, cần nhớ gỡ lệnh chặn khi site chính thức hoạt động.
Không bắt buộc, nhưng nên có để kiểm soát quyền truy cập của bot, đặc biệt là với website lớn, nhiều URL.
Sử dụng Google Search Console (công cụ “Kiểm tra URL” hoặc “robots.txt Tester”) để đảm bảo cấu hình hợp lệ.
Không. Nó chỉ mang tính khuyến nghị cho bot. Nội dung nhạy cảm cần được bảo vệ bằng các phương pháp bảo mật thực sự như xác thực người dùng.